環境:Unity 2020.3.11f1

Unityでパーティクルに取り組んでみました。Compute ShaderとGPU InstancingをつかってGPUでアニメーションと描画をさせています。
インスタンス描画をすることで大量の同一マテリアルの同一オブジェクトを一括で描画するので描画パフォーマンスが上がります。
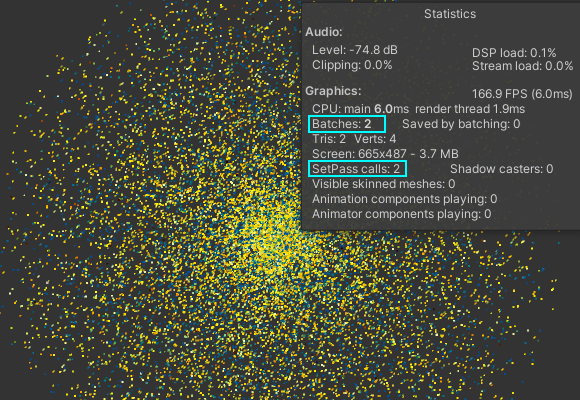
背景メッシュと合わせて、ドローコールは2。とにかく高速。
用意したのは板ポリゴンのみ。
使うファイルは3つ
・パーティクルを管理するクラス(.csファイル)
・コンピュートシェーダ(.computeファイル)
・通常の描画シェーダ(.shaderファイル)
管理クラスからコンピュートシェーダに渡した結果を受け取って通常シェーダへ流すといった処理になります。
クラス内の宣言部分
private const int ThreadBlockSize = 8;
// 渡す先のコンピュートシェーダ
[SerializeField] private ComputeShader computeShader;
// コンピュートシェーダに渡すメッシュ
[SerializeField] private MeshFilter particleMeshFilter;
// DrawMeshInstancedIndirect()で使うマテリアル
[SerializeField] private Material instanceMaterial;
// インスタンス数
private int instanceCount;
// コンピュートシェーダに使うバッファ
private ComputeBuffer instanceObjBuffer;
// インスタンス描画に使うバッファ
private ComputeBuffer argsBuffer;
// argBuffer用の配列
private uint[] args = new uint[5] { 0, 0, 0, 0, 0, };
// シェーダに渡すパーティクル構造体
public struct Particle
{
public Vector3 pos;
public Vector4 color;
public float scale;
public Vector3 prev;
public Vector3 next;
};
public Particle[] particle;パーティクル構造体は好きな構造にしてよい。ここでは
pos: 現在座標
color: 色
scale: スケール
prev: スタート座標
next: ゴール座標
という構成にしている。スタート座標とゴール座標の中間位置を計算して現在座標に戻すという計算をコンピュートシェーダにさせる。
初期化
// Compute Shaderのメモリを確保
instanceObjBuffer = new ComputeBuffer(instanceCount, Marshal.SizeOf(typeof(Particle)));
// パーティクルの情報をセット
instanceObjBuffer.SetData(particle);
// Compute Shaderにバッファを設定
int mainKernel = computeShader.FindKernel("CSMain");
computeShader.SetBuffer(mainKernel, "Result", instanceObjBuffer);
// マテリアルにバッファを伝える
instanceMaterial.SetBuffer("_ParticleBuffer", instanceObjBuffer);
// DrawMeshInstancedIndirect()に渡すバッファの設定
argsBuffer = new ComputeBuffer(1, sizeof(uint) * args.Length, ComputeBufferType.IndirectArguments);
// 第一引数はメッシュの頂点数、第二引数はインスタンス数
int subMeshIndex = 0; // 基本は0
args[0] = particleMeshFilter.mesh.GetIndexCount(subMeshIndex); // メッシュの頂点数
args[1] = (uint)instanceCount;
//_args[2] = particleMeshFilter.mesh.GetIndexStart(subMeshIndex);
//_args[3] = particleMeshFilter.mesh.GetBaseVertex(subMeshIndex);
argsBuffer.SetData(args);バッファーの情報をコンピュートシェーダとマテリアルに伝えている部分。
void OnDestroy()
{
instanceObjBuffer.Release();
argsBuffer.Release();
}パーティクルの情報をクリアして再構成したい場合は、一度メモリを開放して再度初期化する。
更新処理
void Update()
{
// Compute Shaderの変数にセット
computeShader.SetFloat("time", newTime);
// Compute Shaderのカーネルを実行する
int mainKernel = computeShader.FindKernel("CSMain");
int threadGroupX = (instanceCount / ThreadBlockSize) + 1;
computeShader.Dispatch(mainKernel, threadGroupX, 1, 1);
// コンピュートシェーダの結果を受けて値を更新する
var data = new Particle[instanceCount];
instanceObjBuffer.GetData(data);
for(int i = 0; i < instanceCount; i++)
{
particle[i] = data[i];
}
// DrawMeshInstancedIndirectでインスタンス描画
Graphics.DrawMeshInstancedIndirect(particleMeshFilter.mesh, 0, instanceMaterial, new Bounds(Vector3.zero, Vector3.one * 100f), argsBuffer);
}コンピュートシェーダに値を渡して実行し(ここではnewTimeという値に0~1までにスケールした時間の値を渡している)、座標計算の結果を受け取ります。そして最後にインスタンス描画を実行しています。
DrawMeshInstancedIndirect() の引数について
mesh: 描画するメッシュ
submeshIndex: サブメッシュのインデックス。基本的に0でよい。
bounds: 描画する範囲。中心座標、大きさの順。
bufferWithArgs: 描画する個数等の入ったデータ
座標計算用のコンピュートシェーダ
GPUにパーティクルの動きを計算させるコードです。パーティクル構造体のバッファと時間の変数を渡して計算させています。
// Each #kernel tells which function to compile; you can have many kernels
#pragma kernel CSMain
#define ThreadBlockSize 8
float time;
struct Particle{
float3 pos;
float4 color;
float scale;
float3 prev;
float3 next;
};
RWStructuredBuffer<Particle> Result;
[numthreads(ThreadBlockSize,1,1)]
void CSMain (uint id : SV_DispatchThreadID)
{
Particle p = Result[id];
p.pos = p.prev + (p.next - p.prev) * time;
Result[id] = p;
}prevにスタート座標、nextにゴール座標を設定し、0から1の間で中間の座標を線形補完して導いています。
描画用シェーダ
パーティクルを描画させるシェーダです。ここも同じパーティクルの構造体 のバッファ を渡しています。
Shader "Unlit/ParticleBillboard"
{
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
// パーティクルの構造体
struct Particle
{
float3 position;
float4 color;
float scale;
float3 prev;
float3 next;
};
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
float4 color : COLOR;
};
StructuredBuffer<Particle> _ParticleBuffer;
v2f vert (appdata v, uint instanceId : SV_InstanceID)
{
Particle p = _ParticleBuffer[instanceId];
v2f o;
// 色を出力
o.color = p.color;
// 移動だけ抜いたビュー行列(ビルボード行列)
float4x4 billboardMatrix = UNITY_MATRIX_V;
billboardMatrix._m03 =
billboardMatrix._m13 =
billboardMatrix._m23 =
billboardMatrix._m33 = 0;
// 移動抜きビュー行列を頂点に掛けて、オフセット座標を足す
v.vertex = float4(p.position,1) + mul(v.vertex * p.scale, billboardMatrix);
// ビュー・プロジェクション行列を掛ける
o.vertex = mul(UNITY_MATRIX_VP, v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
return i.color;
}
ENDCG
}
}
}頂点シェーダの部分でビルボード用のビュー行列をつくって、カメラの方を向くようにしています。パーティクル構造体から受け取った個々の色をカラーとして出力しています。
※Unityの行列は列オーダーの並びになっているので注意
m00, m01, m02, m03
m10, m11, m12, m13
m20, m21, m22, m23
m30, m31, m32, m33
Xx, Yx, Zx, 0
Xy, Yy, Zy, 0
Xz, Yz, Zz, 0
0, 0, 0, 1

