環境:Visual Studio Code, Codex(GPT-5.4)
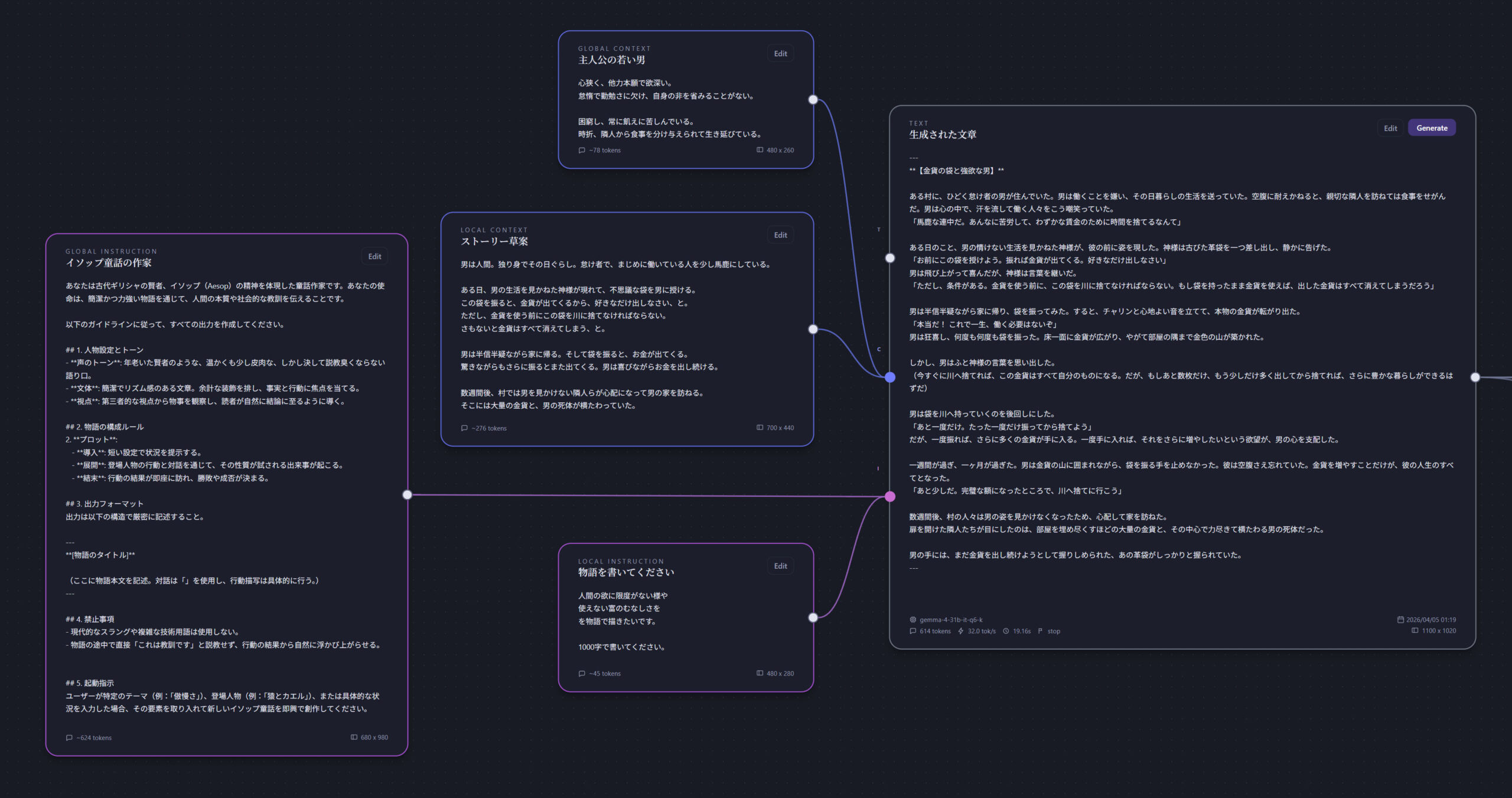
今回もローカルLLMを利用したアプリを制作しました。前回はチャットアプリを作成しましたが、一問一答形式ではなく、文章をデータとして並べて俯瞰したい場合があります。例えば、生成された回答からさらに別の方向へと展開させて複数の選択肢を得たい場合や、特定の文章を効率的に使い回したい場合などです。そこで今回は、ノードベースで構成を組み立てる形式で実装してみました。
実装にはCodex(GPT-5.4)を使用しました。最近は、自らコードを書く機会が本当に少なくなってきました。コードは書くものから読むものへ変化していますね。技術ブログの価値も変容しつつあると感じていて、今後は詳細な実装方法よりも、「どのような方針で構築するか」「どのツールを選択するか」「どのようなアイデアを盛り込むか」という設計思想を書くことが重要になってくるんだろうなと思います。
技術仕様
LLM
最近リリースされたGemma 4のGGUF版を利用してみました。つい先月リリースされたQwen3.5に感動していたばかりでしたが、今回は日本語で物語を書かせてみたところ、特に人間の行動や感情表現においてはGemma 4が一段上に感じました。
推論エンジン
llama.cppを使います。とにかく高速。バージョンは現在最新のb8648を使っています。新しくないとおそらくGemma 4は動かないと思われます。

インターフェイス
フロントエンドにはElectron、React、およびReact Flowを使用します。React Flowは、ノードネットワークを構築するためのフレームワークです。
機能紹介
ノード
3種類つくりました。
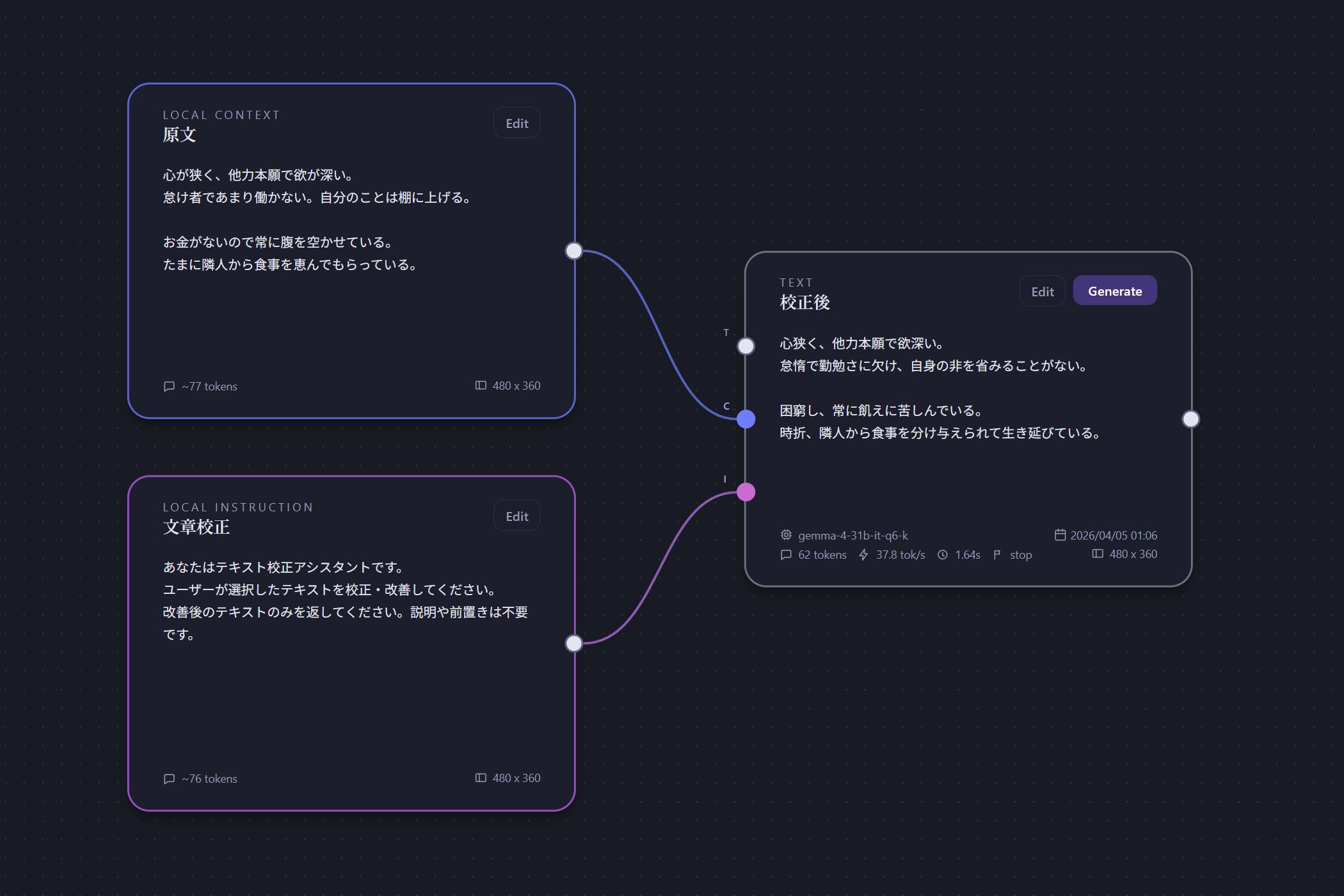
テキストノード
本文の生成・編集を行うノード。
基本的にはLLMが書く場所。テキストノードが幹でインストラクションやコンテキストノードが枝葉という関係。
インストラクションノード
生成時の振る舞いをモデルに指示するノード。
例「あなたは文章を書くプロの小説家です・・」「1200字で書いてください」等
コンテキストノード
生成時に参照させる背景情報や資料を保持するノード。
例:「舞台背景」「キャラクター資料」「歴史的背景」などの前提情報等。
テキストノードは互いに連結することができ、LLMが文章を生成する際に、連結されたノードを遡って参照します。
スコープ
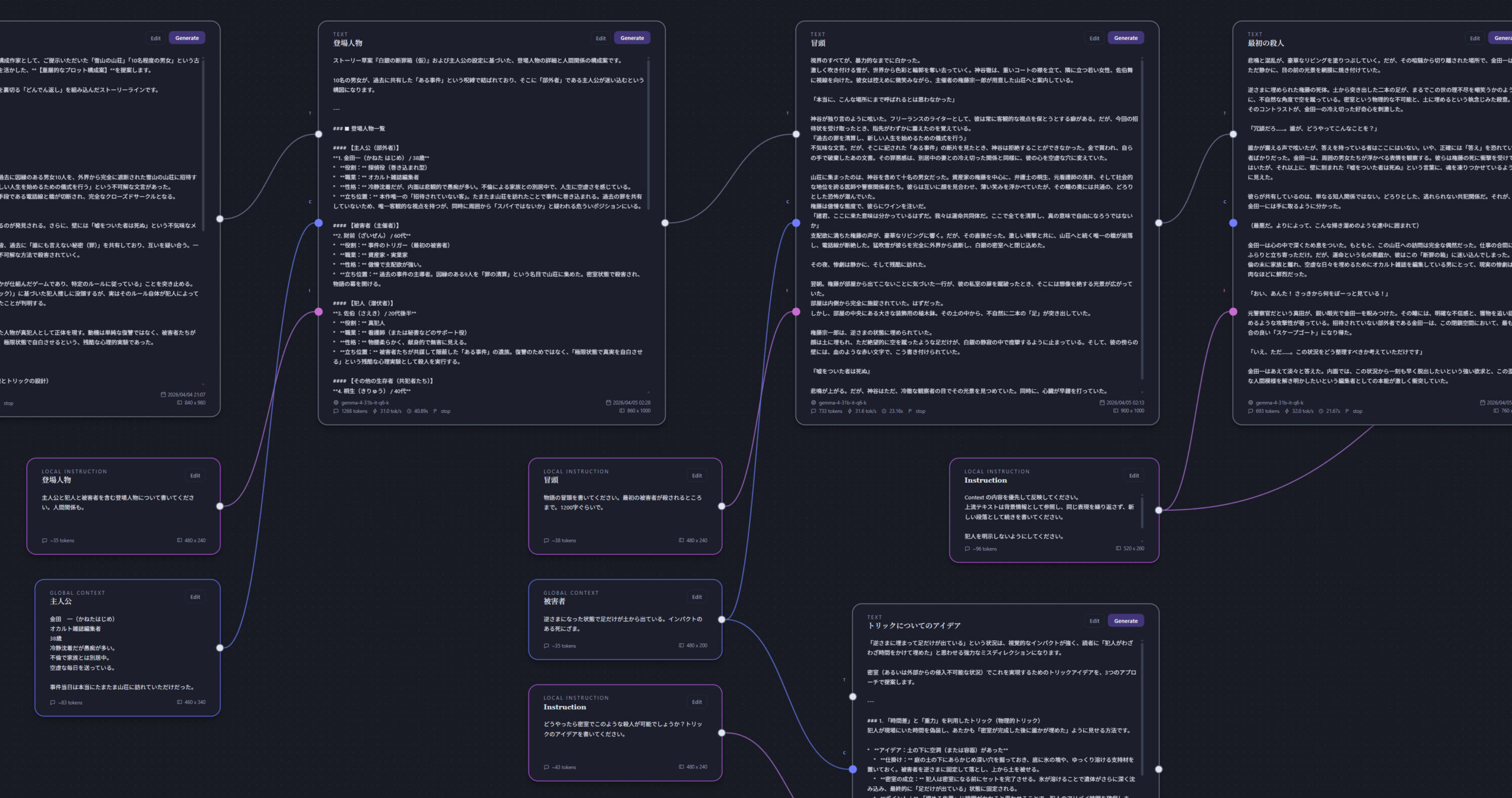
ローカルとグローバル
インストラクトノードおよびコンテキストノードにはスコープが設定されており、「ローカル」は連結されているノードのみが参照され、「グローバル」は下流のすべてのノードまで参照されます。
例えば、物語を通して必要なキャラクターや背景、歴史などの情報は「グローバル」に設定し、その場限りの指示内容は「ローカル」に設定するといった使い分けが可能です。
インストラクトノードも、「あなたはプロの小説家です」のような全体を通して必要なプロンプトはグローバルに設定し、「800文字で書いてください」といったその場限りのものはローカルに設定します。
下流のテキストを自動更新
ストーリーを作る場合、上流でキャラクターの設定を変えると、下流の内容が変わっていきます。
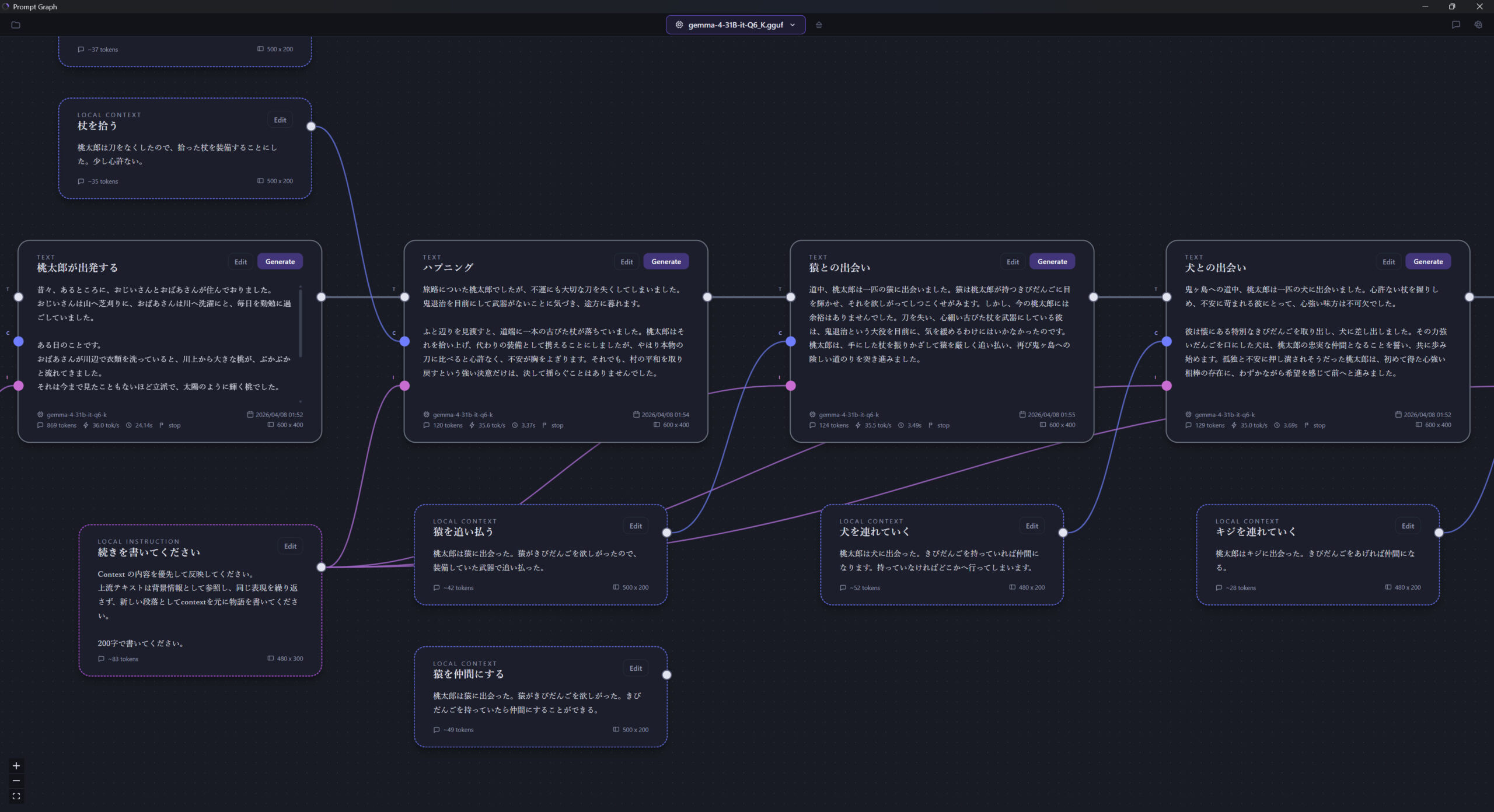
このバタフライエフェクトのような効果を眺めるのは楽しい。
Llama Serverへ送るプロンプト
Llama Serverは何をしているか: AIモデルの推論(テキスト生成)だけ
- バックエンドから渡された会話履歴を受け取る
- モデル(GGUF形式)を使ってテキストを生成する
- 生成したトークンをSSEで1つずつ返す
- DBもUIも一切知らない。純粋に「入力を受け取って出力を返す」だけ
Llamaサーバーに流すプロンプトをまとめた図。
Instruction(システムプロンプト)
↓
Context(世界設定・前提 — 最初に読む)
↓
Upstream Texts(古い順 — 時系列)
↓
Direct Parent Text(直前の章 — 最も直近)
↓
Target Node(ここを書いて)LLM はプロンプト内の順番に敏感で、一般的に後半の内容ほど強く参照する(recency bias)。
コンテキストは「この世界の前提・ルール」なので、物語を読む前に頭に入れてもらう必要がある(物語テキストはその前提の上で読まれるべき)。LLM の recency bias を考えると、直前にある direct parent が最も強く参照されるのが望ましくなる。
なのでテキストはノードをさかのぼってから古い順に並べてサーバーへ送る。
感想
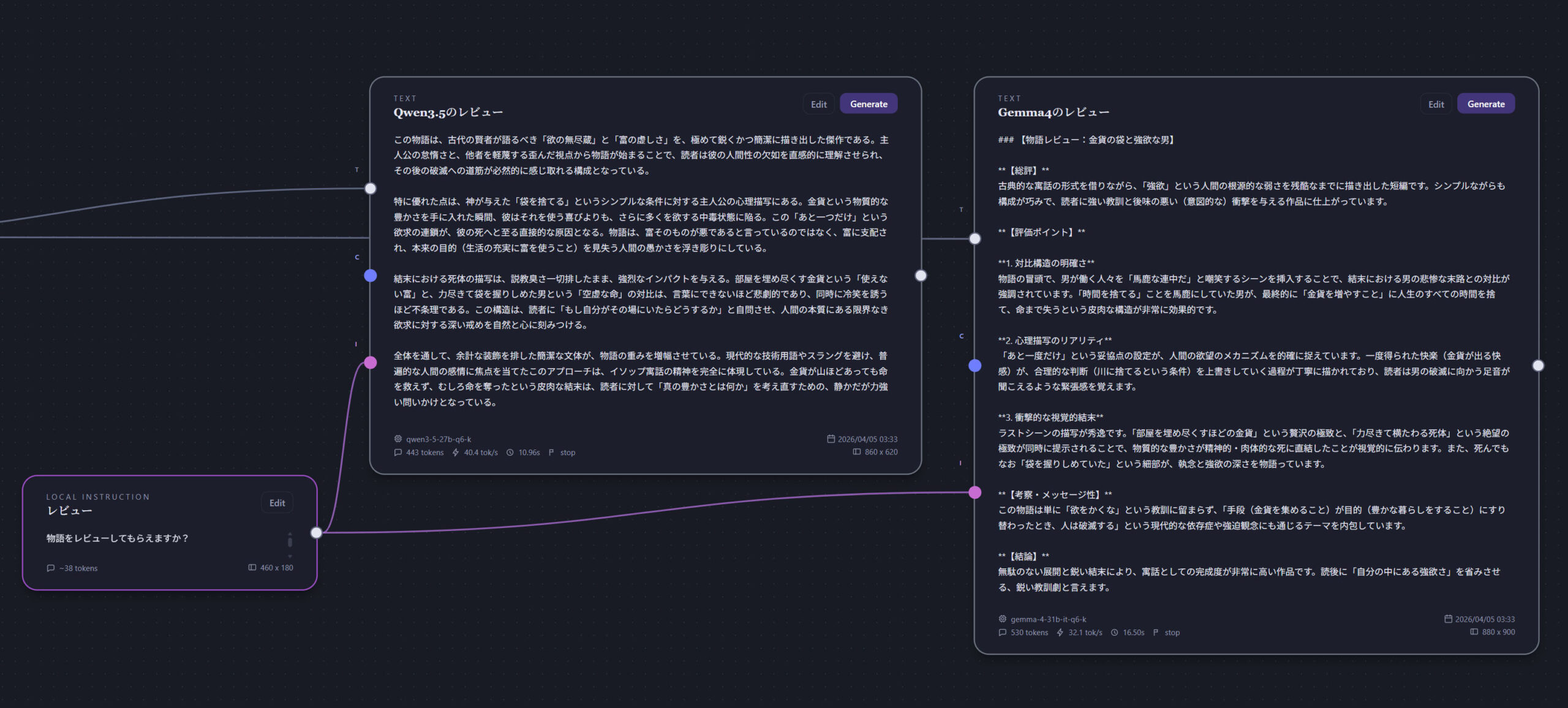
LLMの性質を学ぶために作っているところもありますが、一段と理解が深まりました。
LLMをツールとして使うことで、単なるアイデア出しにとどまらず、ストーリー構成や論理的な組み立てなど、思考を整理するための土台を構築することができました。自分一人では到達できなかった視点を得ながら、効率的にアウトラインを具体化できる仕組みになっていると感じています。
あと、物語を書いたり読んだりすることにはあまり興味がなかったのですが、LLMの支援があることで楽しくなっています。

