環境:LM Studio 0.3.36
ローカルLLMを始めるにあたって、わかりやすくて簡単なツールのひとつが LM Studio です。LLMとは何なのか、その性質や特徴を学ぶ入門用としてもちょうどよいツールだと思います。
日常や仕事ではChatGPTやClaudeなどのオンラインLLMを使っているわけですが、プライベートではローカルLLMも利用しています。
ローカルLLMの主なメリット
無料、無制限
初期投資(GPUや電気代)はかかるが、その他はほとんどお金がかからない。
プライバシーと機密性
入力データが外部サーバーに送られないのでセキュリティー的に安心。
外部からの変更の影響を受けない。技術職や制作系には大きな利点。
モデルを自由に選べる・改造できる
個人的にここが一番の利点。量子化モデル、無検閲化モデル、LoRA等、いろいろなモデルを試せる。カスタマイズすることもできる。道具としてコントロールでき、所有感がある。
検閲フィルターを除去した無検閲化モデルを使うことができるのは大きなメリットです。例えば創作のための調べものをしているとChatGPTでは「その質問にはお答えできません・・・」と断わられてしまうことがあります。オンラインだと配慮が必要になる質問も、オフラインなら他人の目を気にせず気軽に試すことができます。
ローカルLLMは例えるならドラえもんだと思っています。ジャイアンに仕返ししたいと相談した時に「そのような考え方はよくない」と説教してくるドラえもんよりも、「このスタンガンを使いなさい!」と危険な道具を渡してくれるドラえもんを求めているんですよね。笑
やっておくべき設定
保存先
プログラムはCドライブにインストールされますが、ダウンロードするLLMモデルは容量が大きいので他のドライブに設定したほうがいいです。
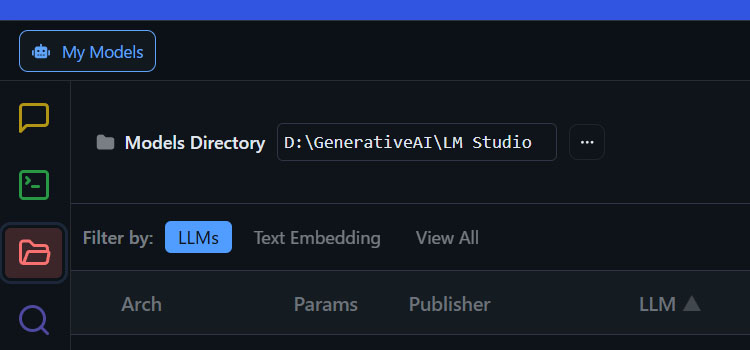
左側のメニューからMy Modelsを選択し、Models Directoryでモデルの保存先を設定する。
意識するべきパラメータ
Context Length
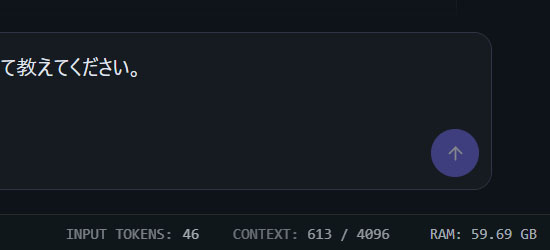
各モデル、各チャットごとに設定可能。デフォルトは4096トークン。これはLLMの記憶データのようなもの。入力と出力のトークンで積み上がっていく。右下に現在のチャットでの割合が表示されており、Context: 4320 / 4096のように最大値を超えてしまった場合はチャットを終えて、新しくチャットを始めるほうがよい。そうしない場合、エラーが起こったり、同じ文章を繰り返したり、ハルシネーションを起こしたりと挙動がおかしくなる(ChatGPTのようなAPIは裏でまとめたりと上手く調整をしているがLM Studioは敢えてそのような仕組みがない)。
設定でコンテキスト長は変更できるが、LLM本体の容量とは別にVRAMの消費量が増える。
ローカルLLMの使い方
個人的なローカルLLMの使い方です。
画像生成AIのプロンプトを書いてもらう
ちょっとしたことを聞くのはAPIより気楽。
画像を分析してもらいプロンプト化する
APIにアップロードするにはちょっと面倒な画像ファイルも気軽に調べることができます。
ちょっとした物語を書いてもらう
登場人物やプロットだけを書いて渡すと、なかなかいいものに仕上げてくれます。まだお遊び程度にしか使ってませんが非常に可能性を感じます。
容量別LLMの雑感
オリジナル(FP16)のモデルファイルは容量が大きすぎるので基本的に量子化されたモデルを使います。Q4_K_Mのようなモデルです。量子化の読み方
| モデル規模 | 対象VRAM | できること |
| 7B級 | 12GB | 短い質問、用語説明 |
| 13B級 | 16GB | 要約、軽い推論ができる |
| 30B級 | 24GB | 複雑な指示ができる、論理に一貫性がある |
| 70B級 | 48GB | 長文・推論・破綻しにくい 文字化けのようなエラーがほとんどなくなる |
まともに使えると思うのは13B以上で、30Bあたりから会話ができる感触があり、70BはAPIに近いと思えます。
LLM(大規模言語モデル)は、画像生成AIと比べると、モデル全体が1枚のGPUのVRAMに収まらなくても動かしやすいという特徴があります。そのため、VRAM容量を少し超えるモデルでも、設定次第で試すことができます。ただし、その場合は処理速度が遅くなることが多く、返答に時間がかかるようになります。
案外CPUとRAMで動かせる
自分のVRAM16GB、RAM128GBの環境でもQwen3-80B(48.4GB)やgpt-oss-120B(63.4GB)のモデルを動かすことができます。RAMがかなり圧迫されますが、ゆっくり文字が生成され、結果や精度を確認することはできます。VRAMから溢れて動作速度が遅くなっても精度優先で大きめのモデルを選ぶということも少なくないです。
おすすめLLMモデル【2025年】
個人的なおすすめモデルです。日本語での使用感です。
| モデル規模 | モデル | できること |
| 13B級 | Gemma-3-12B(8.15GB) / Google( 2025-3) | 12Bと思えないぐらい自然な返答が返ってきます。単発の質問なら軽くて便利です。ビジョンモデルなので画像の解析もできます。「この画像からStable Diffusionのプロンプトをつくってください」のような使い方ができます。 |
| gpt-oss-20b(12.11GB) / OpenAI(2025-8) | さすがOpenAIです。この容量なのに結構まともな性能です。検閲フィルターは厳しめ。APIのChatGPTとどうしても比較してしまうので見劣りはしてしまう。 | |
| 30B級 | Nemotron 3 Nano(24.5GB) / nVidia(2025-12) | nVidiaのモデル。容量に対してなかなか真面目で賢い回答が返ってくる印象。安定しており、脱字が少ない。 |
| Qwen3-VL-30B(19.64GB) / Alibaba(2025-10) | 30Bクラスのビジョンモデルとして画像解析に重宝している。 | |
| 70B級 | Qwen3-Next-80B(48.4GB) / Alibaba(2025-9) | 誤字もほぼなく、非常に自然な会話ができる。 |
おすすめLLMモデル【2026年3月】※追記
2026年3月現在のおすすめはQwen3.5シリーズです。圧倒的です。
| モデル規模 | モデル | できること |
| 9B級 | Qwen3.5-9B(6.55GB) / Alibaba( 2026-3) | 9Bと思えないぐらい自然な返答が返ってきます。おかしな日本語も少ない。ビジョンモデルなので画像の解析もできます。 |
| 27B級 | Qwen3.5-27B(15.4GB) / Alibaba(2026-3) | 完成度の高い賢いモデルです。去年までのローカルLLMだからクオリティが低くても仕方ないか、を感じさせない出来です。 |
感想
ローカル環境で人工知能と会話ができるなんて少し前まで考えられなかったですよね。
ローカルLLMは次々と新しいモデルが登場しており、今後も楽しみな分野です。モデルは単に肥大化するだけでなく、容量が小さくなりながらも賢さが増す方向へと進化しています。どんどん便利になって欲しいですね。
応用
LM StudioをAPIサーバにしてVSCode上でLLMと一緒にコードや文章を編集できるようにします。
ローカルLLMにウェブ検索をさせる方法です。便利さが変わります。

