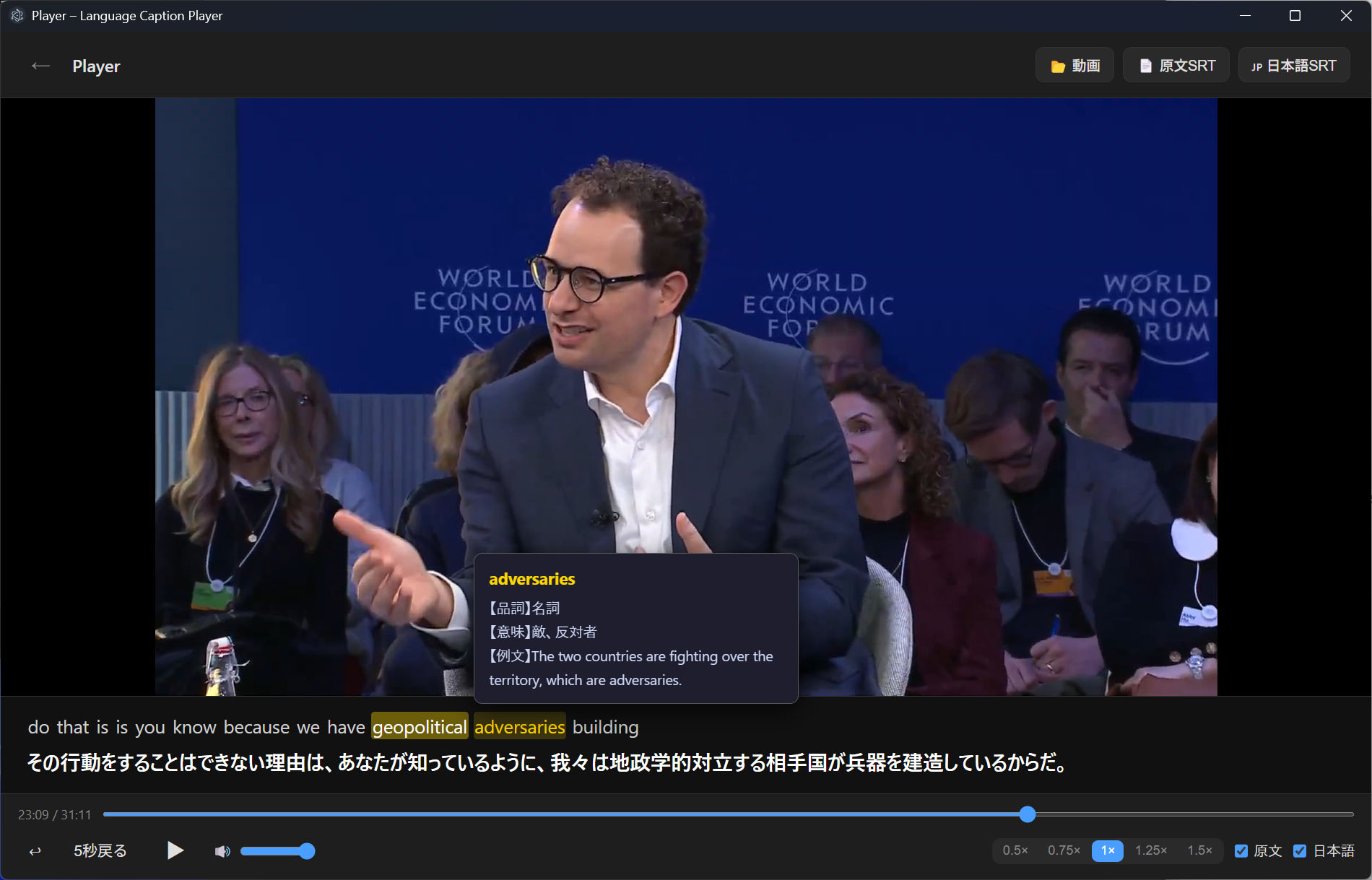
環境:Visual Studio Code, Claude Code(Sonnet 4.6)
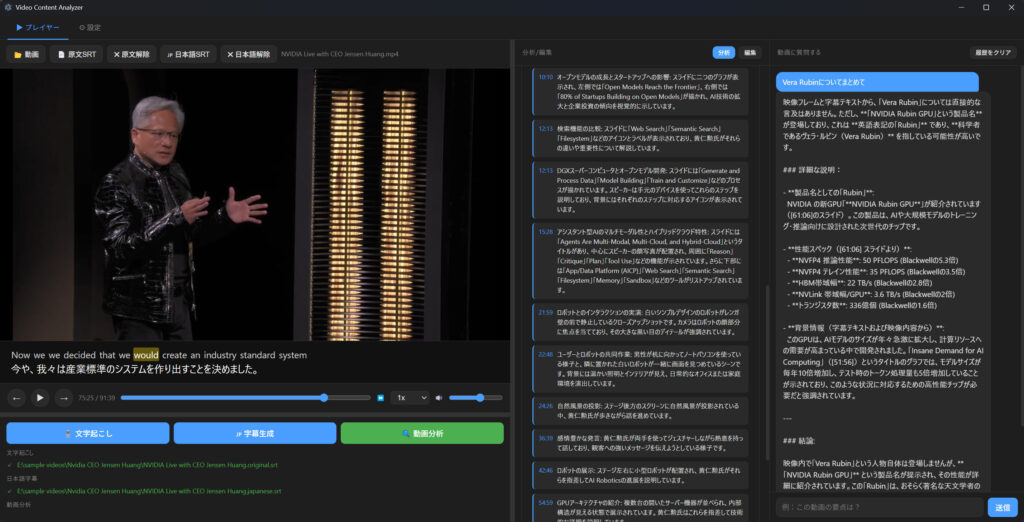
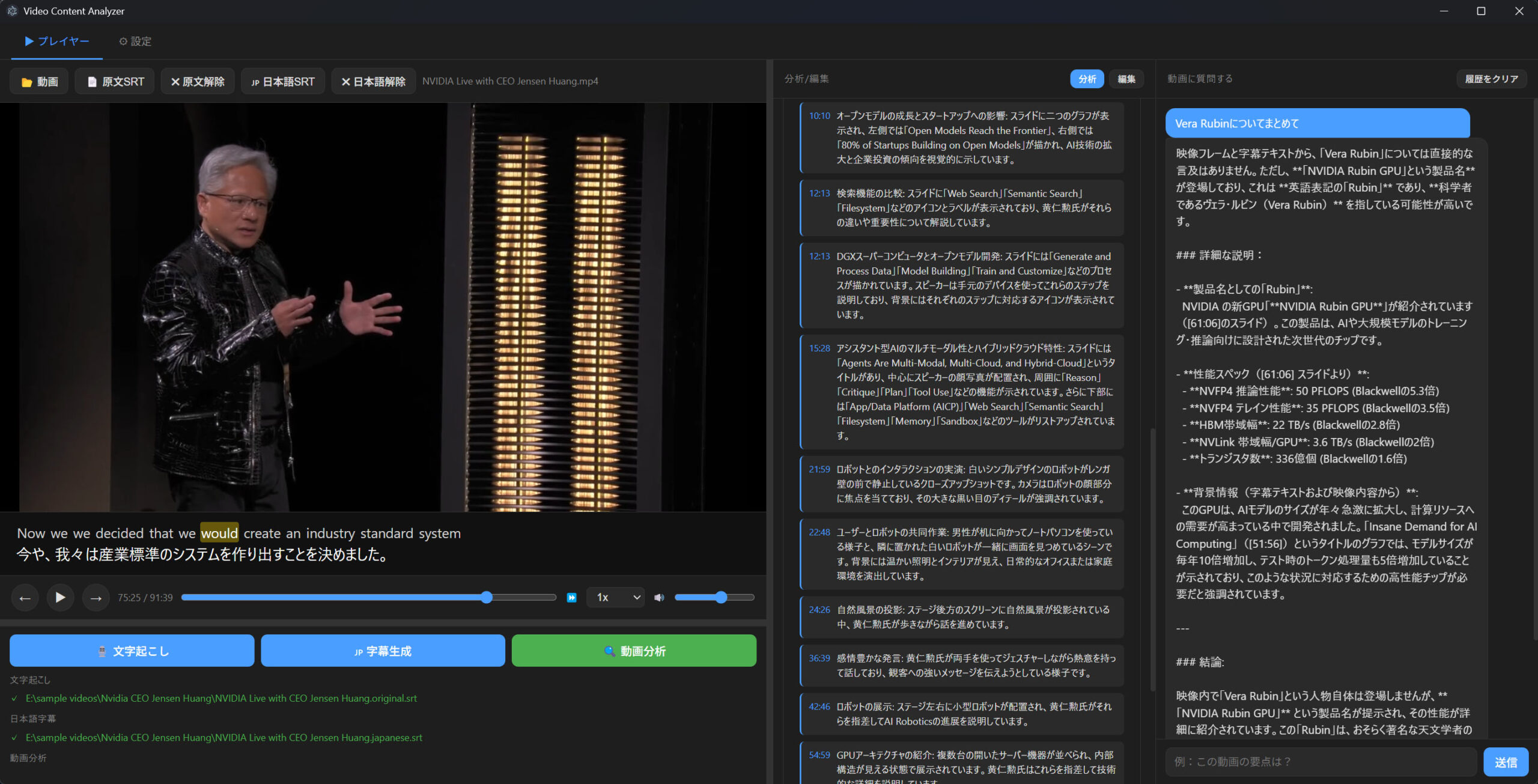
以前からやってみたかった視覚言語モデルによる動画の解析をやってみました。前日の試作を拡張したものになります。
Qwen3-ASRを使って動画音声の文字起こしをする
仕様
今回利用したモデルは以下
・Qwen3-VL 8B(動画解析)
・Qwen3-ASR 1.7B(音声解析)
やらせてみたことは
・動画の内容を時系列で描写させる
・動画の目次を自動で作る
内容の精度を上げるために音声解析モデルも補助的に利用しました。
目次の作成には音声内容も利用しています。
フロントエンド:Electron
バックエンド:FastAPI
推論エンジン:Transformers, PyTorch
実装
ほとんどClaude Codeに組み立ててもらったのですが、動画を解析するといっても動画を1フレームずつ読ませるわけにはいかないらしく、均等サンプリングで動画全体から均等にN枚画像を切り出してモデルに渡す方法と、シーン検出というカットが変わるところをFFmpegを使って検出して代表カットを抜き出して渡す方法の2つを採用しました。
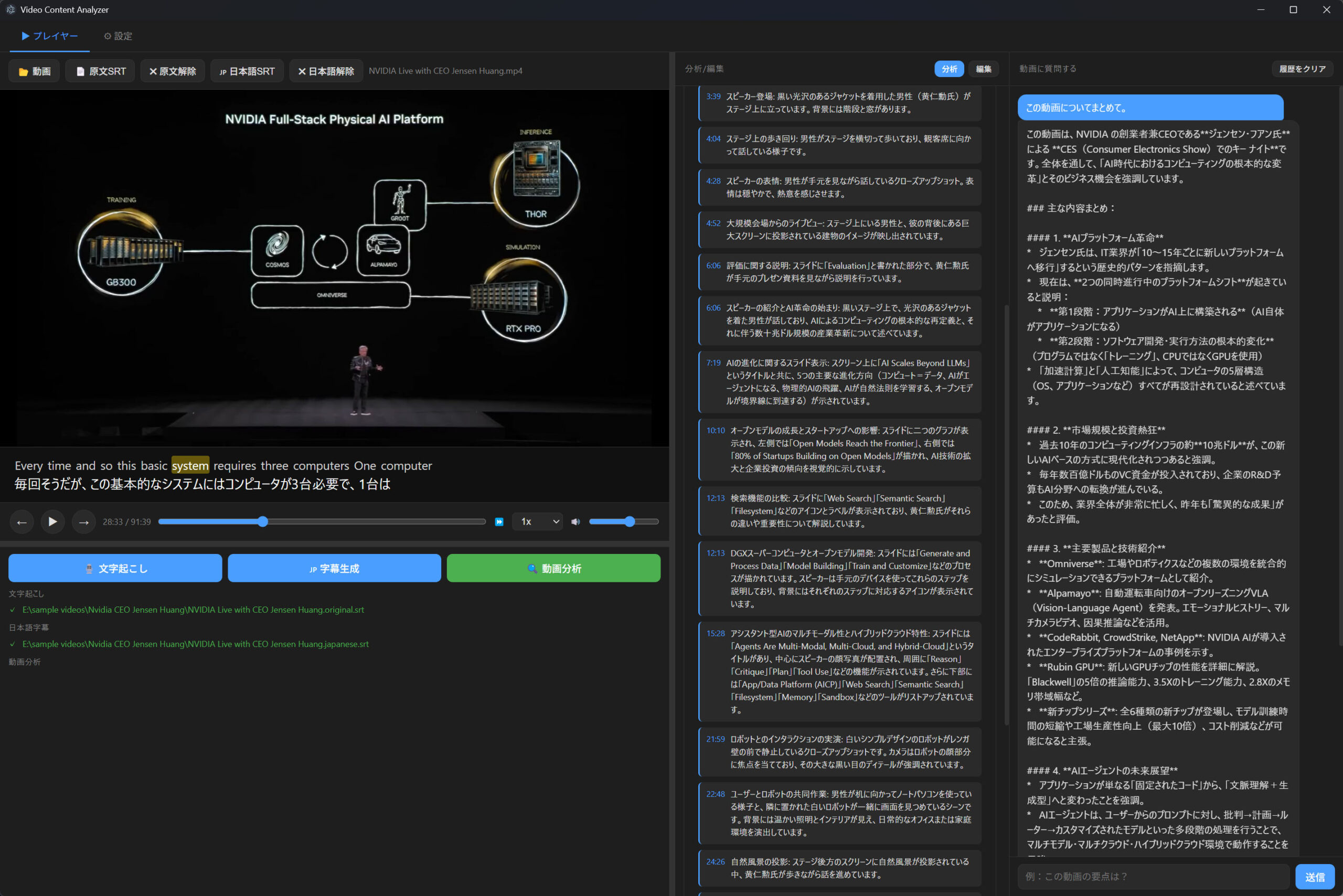
結論から言うと、精度の高い目次の作成は結構難しかったです。タイムスタンプと少し内容がずれます。ランダムにサンプリングした位置にどうしても縛られてしまうので仕方がないのかもしれない。
感想
視覚言語モデルだけでも結構よい結果が出ましたが、やはり音声解析との組み合わせで精度の高い結果がでますね。視覚言語モデルへの理解が深まり、今後のコンテンツへの応用が出来そうで収穫がありました。