環境:Visual Studio Code 1.108.2, Claude Code
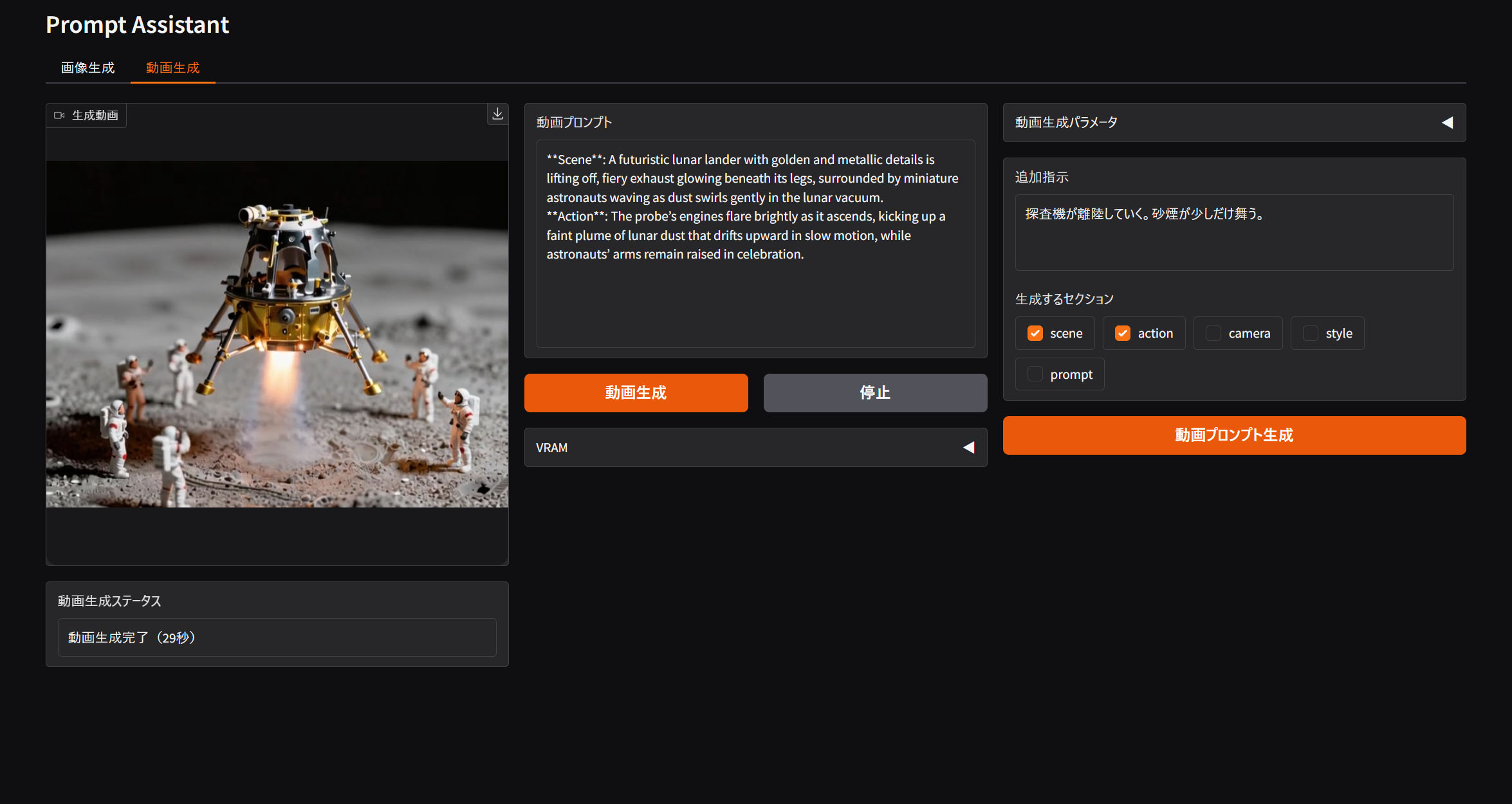
前回と同様、ローカルLLMを使って動画向けのプロンプトを生成するアプリをつくりました。今回は対話をするのではなく、解答だけを返します。LLMを完全にツールとして使いました。
使っているモデルはQwenのビジョンモデル、Qwen-3-VL 4B(容量8.3GB)です。対象としている動画モデルはWAN2.2です。
Stable Diffusionの画像を使う
ベースは前回作成したアプリを元にしています。
https://technical-notes.com/generative-ai/2026/01/31/stable-diffusion-prompt-analyzer/
インターフェイスは対話式ではなく、入力に対して結果の文章が出てくる形式に変更しました。
「Stable Diffusionの画像」+「Stable Diffusionのプロンプト」+「動画への指示」をローカルLLMがよい感じに動画用のプロンプトに構成します。結果が気に入るまで、なんども文章を修正できます。
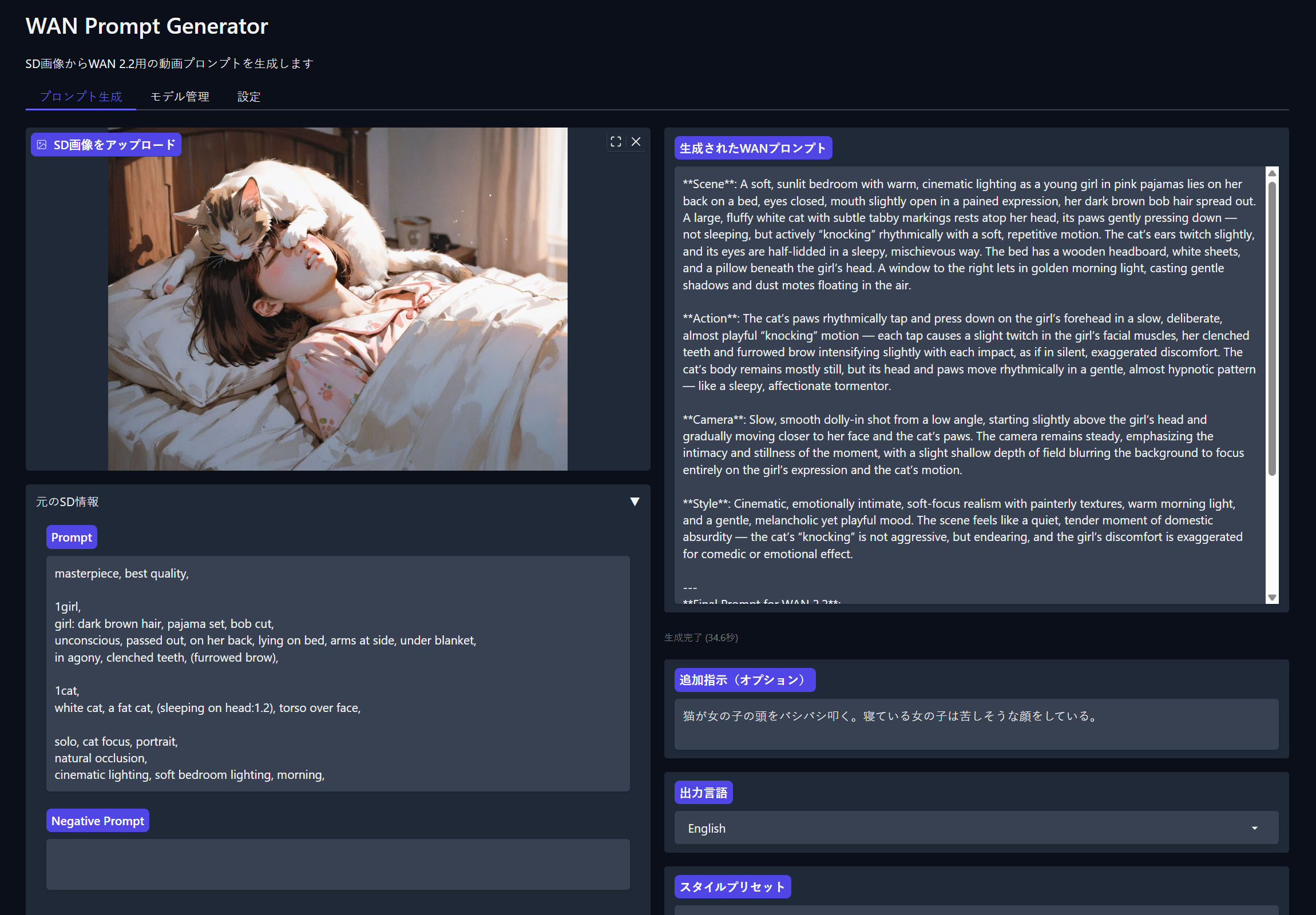
「猫が女の子の頭を叩く。寝ている女の子は苦しそうな顔をしている」という指示を出して、動画用の英語プロンプトが生成されました。プロンプトは英語・日本語を切り替えられるようにしています。
生成されたWAN用のプロンプトをComfyUIでそのままプロンプトとして入力します。
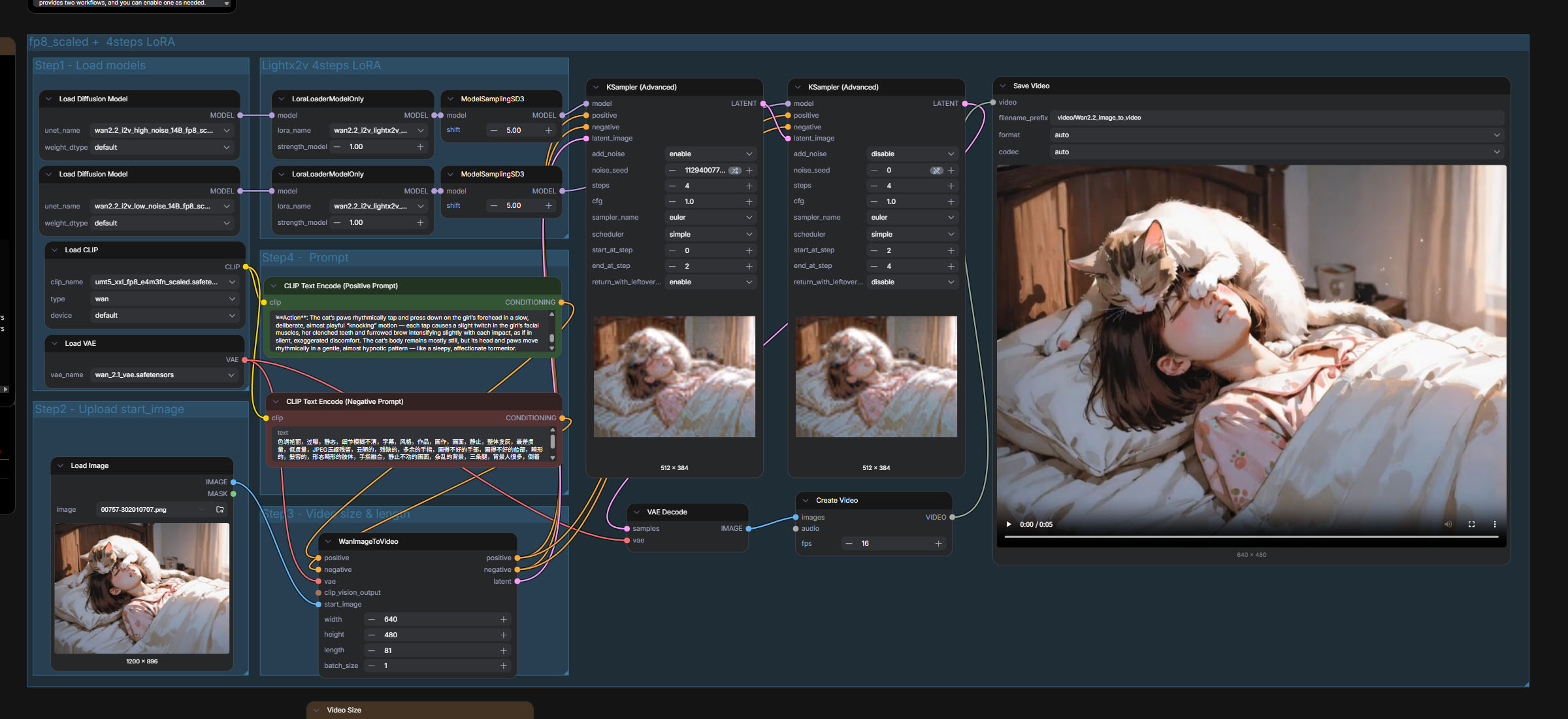
一般的な画像を使う
Stable Diffusionだけでなくどんな絵でも入力できるようにしました。プロンプトがなくてもビジョンモデルが絵から状況を解釈してくれます。
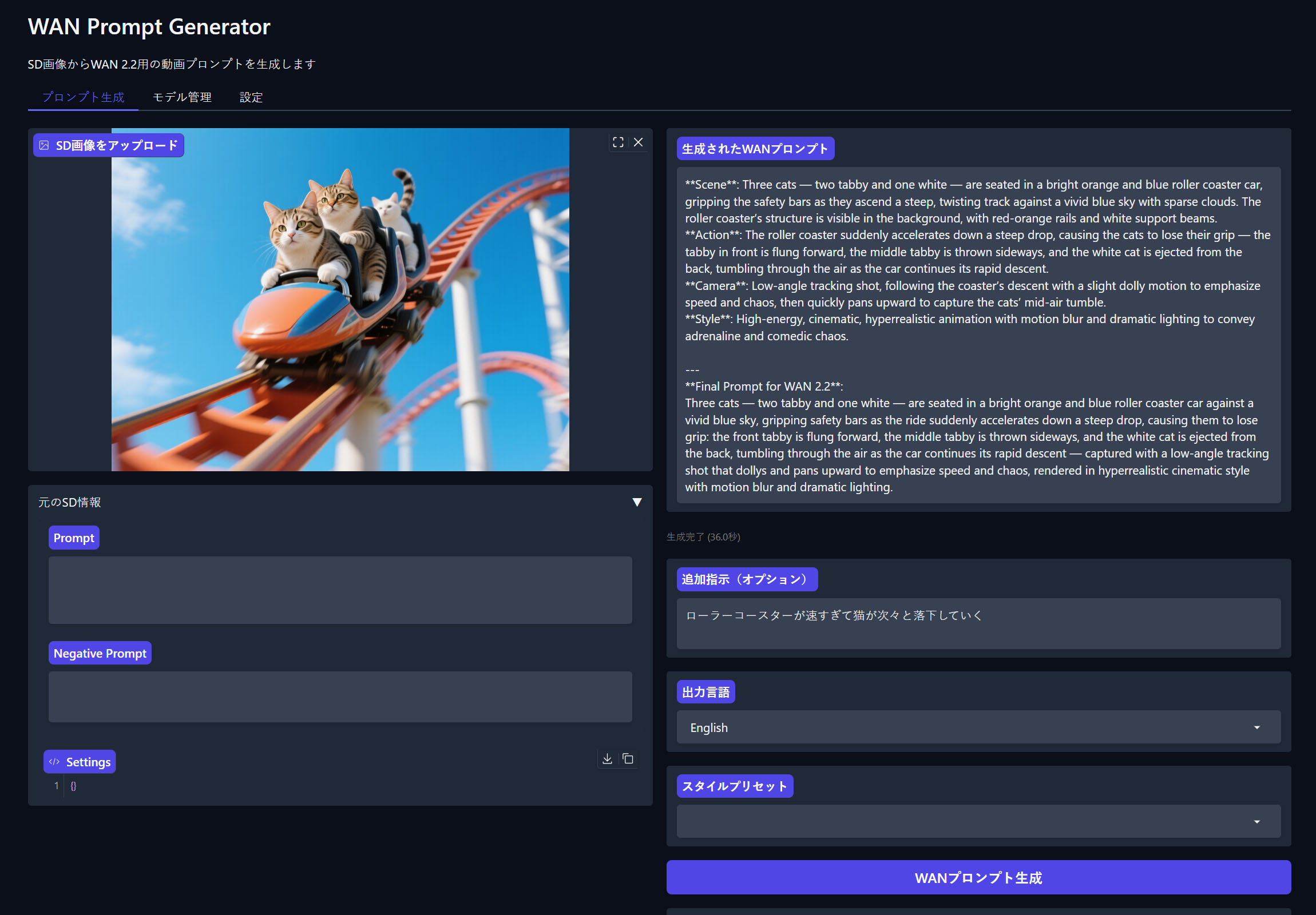
Qwen-Imageで作成した猫のローラーコースター画像を使ってみます。

「ローラーコースターが速すぎて猫が次々と落下していく」という指示を書いて、プロンプトを生成。

絵の状況と合わせて適切な動画向けのプロンプトが生成されます。
こんどはケンカさせてみました。
仕様
リポジトリはこちら

Gradio:機械学習モデル向けのWeb UI作成ライブラリ
PyTorch:機械学習(深層学習)ライブラリ
pillow:画像処理ライブラリ
huggingface-hub:Hugging Face Hubから モデル・データセットを取得・管理
qwen-vl-utils:Qwen系の Vision-Languageモデル向け補助ツール(Qwen VLモデル)
torchvision:画像処理・CV向けPyTorch拡張ライブラリ
感想
手動でプロンプトを書いていた時よりもだいぶ指示通りに動いてくれるようになって楽になりました。表現力もあがりました。LLMを使うと文章をプログラミングしている感覚になりますね。
いやしかしClaude Codeが楽しすぎてAIコーディングにハマってしまいました。Claudeがプログラマーで自分はデバッガーという役割分担になってますが。
もうここ数年だいぶプログラミングに飽きていて、いよいよモチベーションが限界に近い時期でした。Claude Codeの支援によって自力では到達できなかったであろう領域に踏み込むことができています。これまで見ることができなかった景色です。業務では十数年にわたって同じことの繰り返しが続いていて、さすがにマンネリ感は否めず。そこに彗星の如く現れたClaude Codeですよ。今年一番の感動でした。まだ一カ月しか経ってないけど。