環境:Visual Studio Code 1.108.2, Claude Code(Opus 4.6)
前回と前々回はプロンプト生成を支援するアプリを作成しましたが、今回はそれらを統合するようなアプリをClaude Codeとつくりました。
概要
前々回
ビジョン言語モデル(Qwen-3-VL)と会話ウインドウを通じてプロンプトを修正してもらいながら理想の絵を生成するアプリ。
前回
画像とプロンプトと追加指示を元にビジョン言語モデルが動画用プロンプトをつくるアプリ。
どちらもビジョン言語モデルに支援してもらいながらプロンプトを作ってもらうという方向性は同じで、生成されたプロンプトをコピペして、Stable Diffusion WebUIやComfyUIに貼り付けて生成していました。
今回はこの面倒な作業を省き、Stable DiffusionおよびComfyUIをバックエンドAPIとして利用し、アプリ側からプロンプトや各種設定を送って裏側で生成された画像・動画を返してもらうという処理の流れをつくりました。
つまりアプリだけで完結するような仕組みにしました。
LLMとの会話:Qwen-3-VL 4B
画像生成:Z-Image Turbo / Qwen-Image / SDXL(Illustrious)
動画生成:WAN2.2
事前準備
Stable Diffusion
Stable Diffusionはディレクトリ直下にあるwebui-user.batの内容を編集する必要があります。
stable-diffusion-webui-forge/webui-user.bat
set COMMANDLINE_ARGS=--apiCOMMANDLINE_ARGSに–apiを追記します。これでAPIとして利用できるようになります。
Stable Diffusionへ渡すデータはプロンプトや縦横サイズ、Sampler、CFG、Seed値と少ないです。WebUIのほうにすでに設定してあるモデルやLoRAが使われることになります。
ComfyUI
ComfyUIへ渡すデータはプロンプトの他、ワークフローのJSONが必要になります。これはComfyUIからエクスポート(API)しておきます。
個人的にはよく使うZ-Image-TurboとQwen-ImageのWorkflowをエクスポートしたJSONをアプリに保存しておきました。また動画生成用にWAN2.2のWorkflowも用意しました。
アプリ側からはプロンプトと縦横サイズ、Seed値をJSONに上書きした情報をAPIに渡します。
画像生成モード
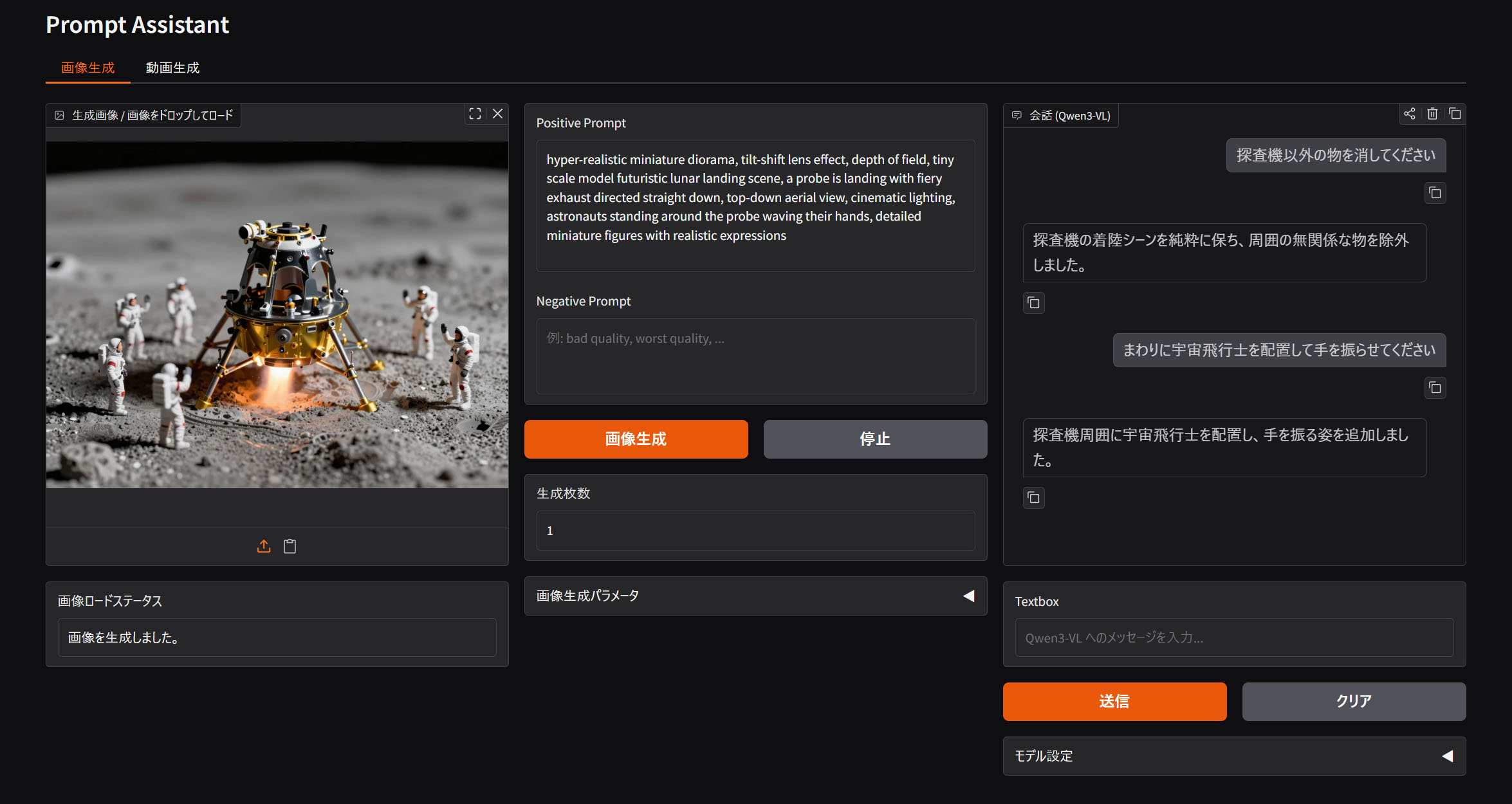
プロンプトをビジョン言語モデルと会話しながら組み立てていきます。画像生成ボタンを押せばStable DiffusionまたはComfyUIから結果が返ってくる仕組みです。生成済みの画像をドロップしてプロンプト等をロードすることもできます。
生成した画像はこちら

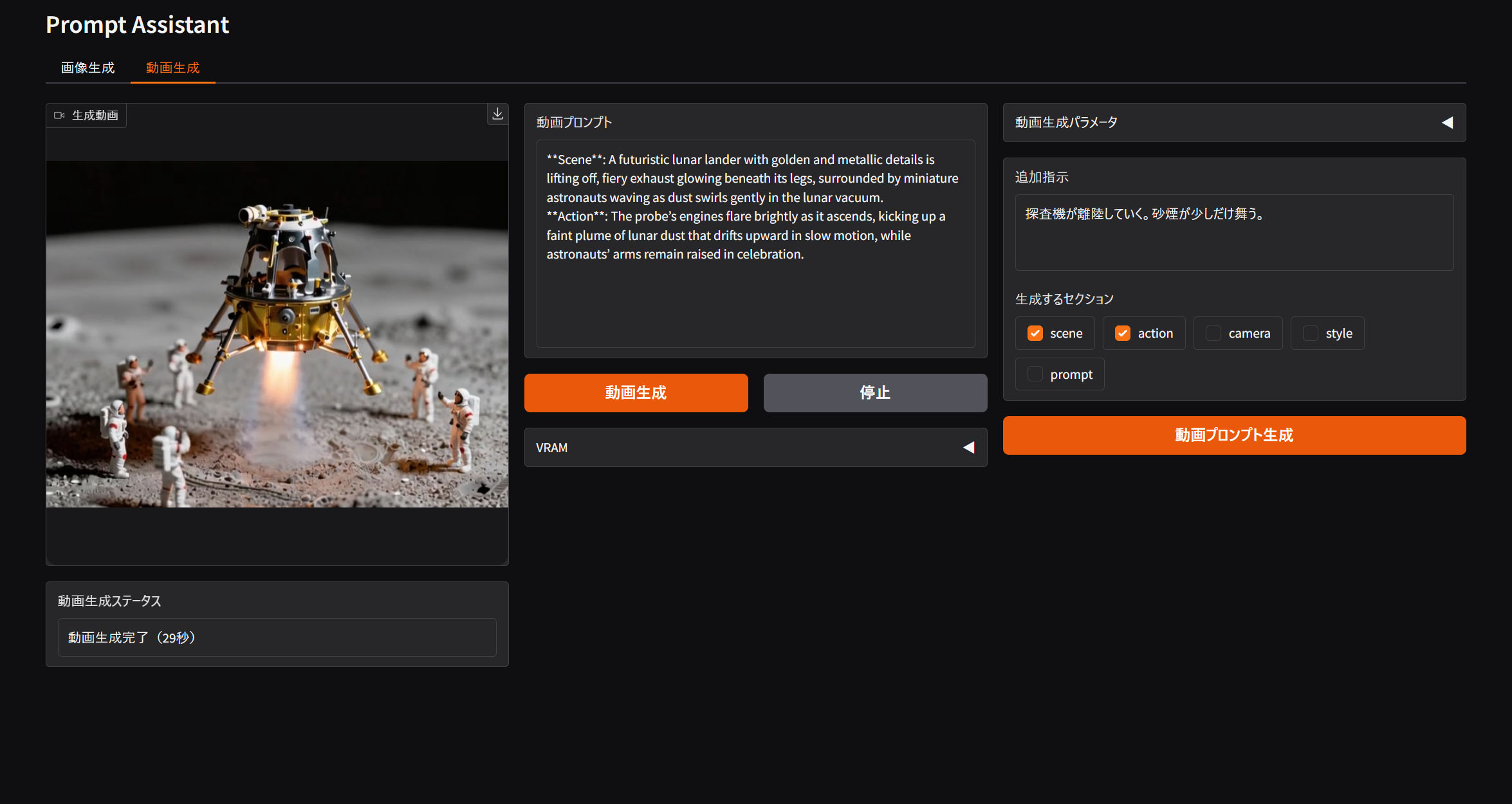
動画生成モード
タブを切り替えると動画生成モードになります。追加指示テキストに動画の流れ等を書き込んでおきます。設定された画像に対してふさわしい動画用プロンプトをビジョン言語モデルが整えてくれます。プロンプトがよい感じに整ってきたら、動画生成ボタンを押してComfyUIに渡します。
ComfyUIにはWAN2.2のWorkflowも渡します。これもサイズやSeed値などを上書きできるようにしてあります。
このアプリを使って生成した動画がこちら。
これでちょっとした短編動画をつくる準備が整いました。
感想
ツールをつくることでプロンプト作成もだいぶ楽になってきました。難点があるとすれば、ビジョン言語モデルに8GB、WAN2.2に30GBが必要になるので、VRAM容量は必須です。
Claude Proプランに入っていますが、アプリを1つ作るとだいたい週制限の15%ぐらい消費します。解決できないエラーのループに入るとどんどん消費されていくので、嫌な予感がしたら無理せず諦めも肝心ですね。