環境:Visual Studio Code 1.108.2, Claude Code
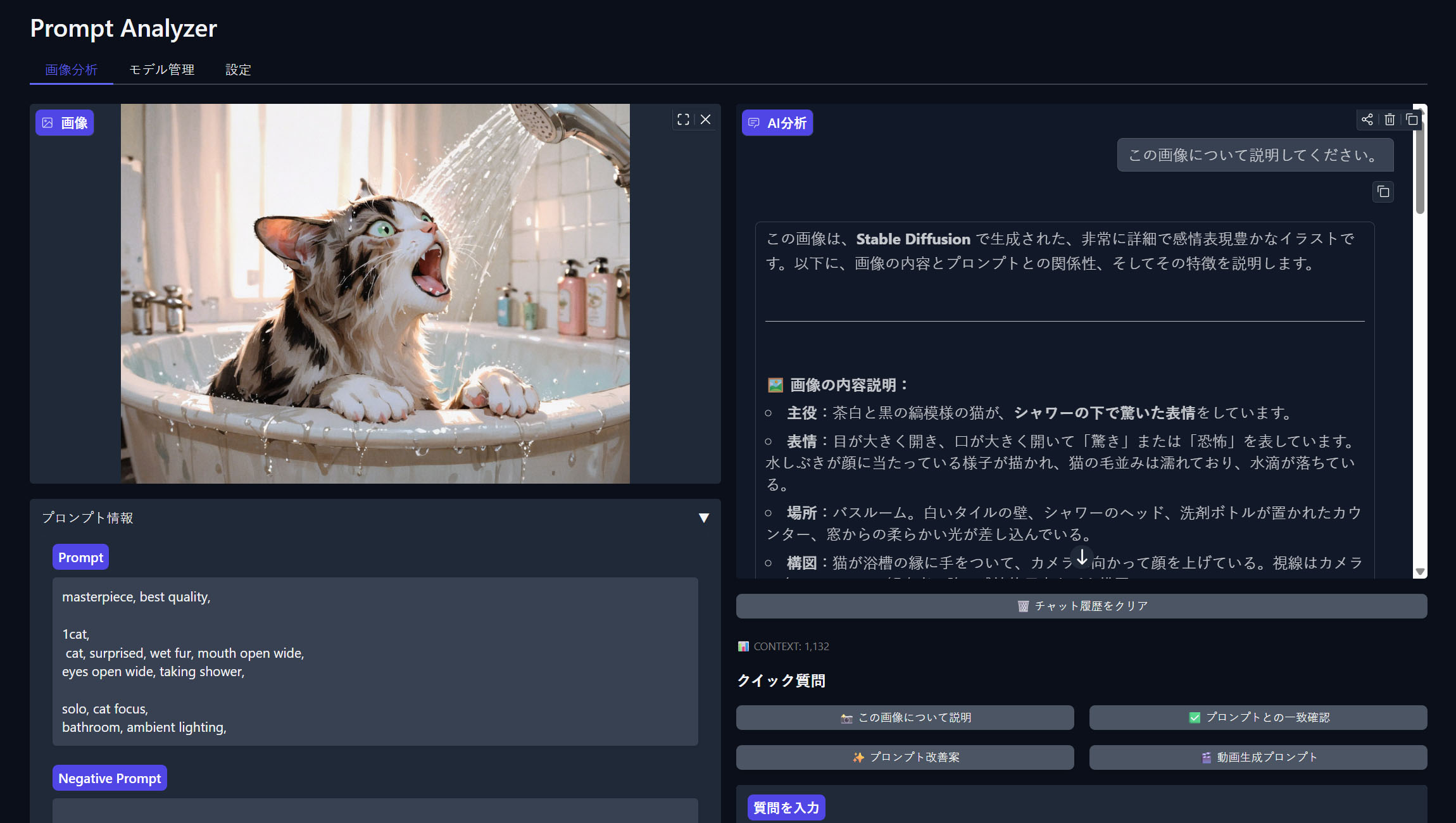
Claude Codeの力を借りて、ローカルLLMモデルを利用したアプリ開発を始めてみました。チャットボットを作ってみたいというのが強い動機です。
チャットボットを使って作ったら面白そうなアプリのアイデアはいろいろあるのですが、まずはStable Diffusionで生成した画像とプロンプトをレビュー・修正・提案するものを作ってみようと思いました。
きっかけ
Stable Diffusionを始めたときに苦労したのはプロンプトでした。適切な単語を探すために、ウェブを検索してプロンプトのリストが載ったサイトを探したりと、やたらと時間を使いました。LLMが画像とプロンプトを同時にレビューして、さらに支援もしてくれたら楽なのになーと思ってたので、そんな悩みを解決するものを目標としてみました。
できること
プロンプトの改善
Qwen-3のビジョンモデルであるQwen3-VLを使っています。画像そのものの評価ができるので、プロンプトとの整合性を評価してもらえます。また修正したプロンプトも依頼することができます。
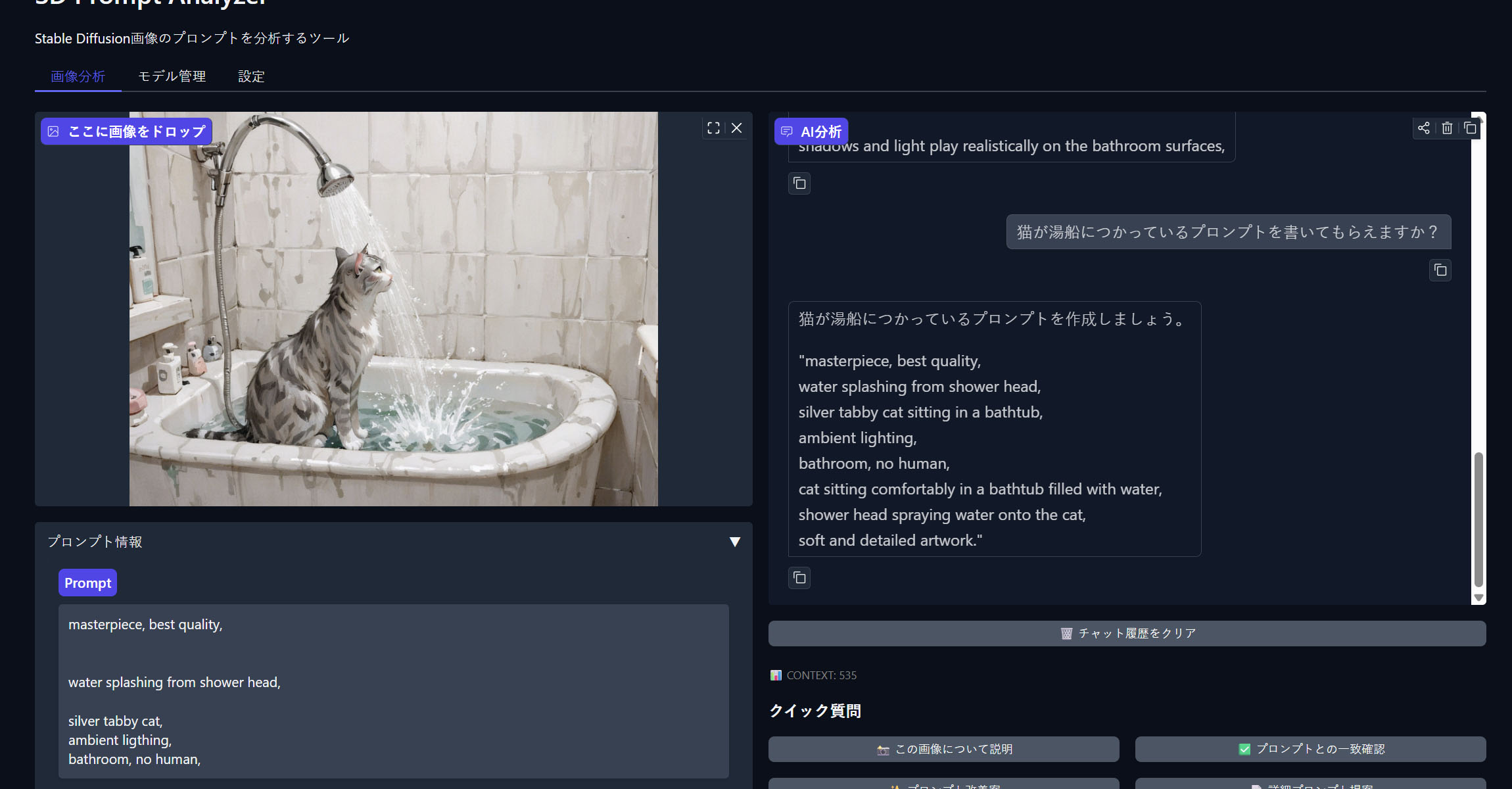
「湯船に浸かっているプロンプトに変更して」と頼めば、元のプロンプトを修正する形で返してくれる。

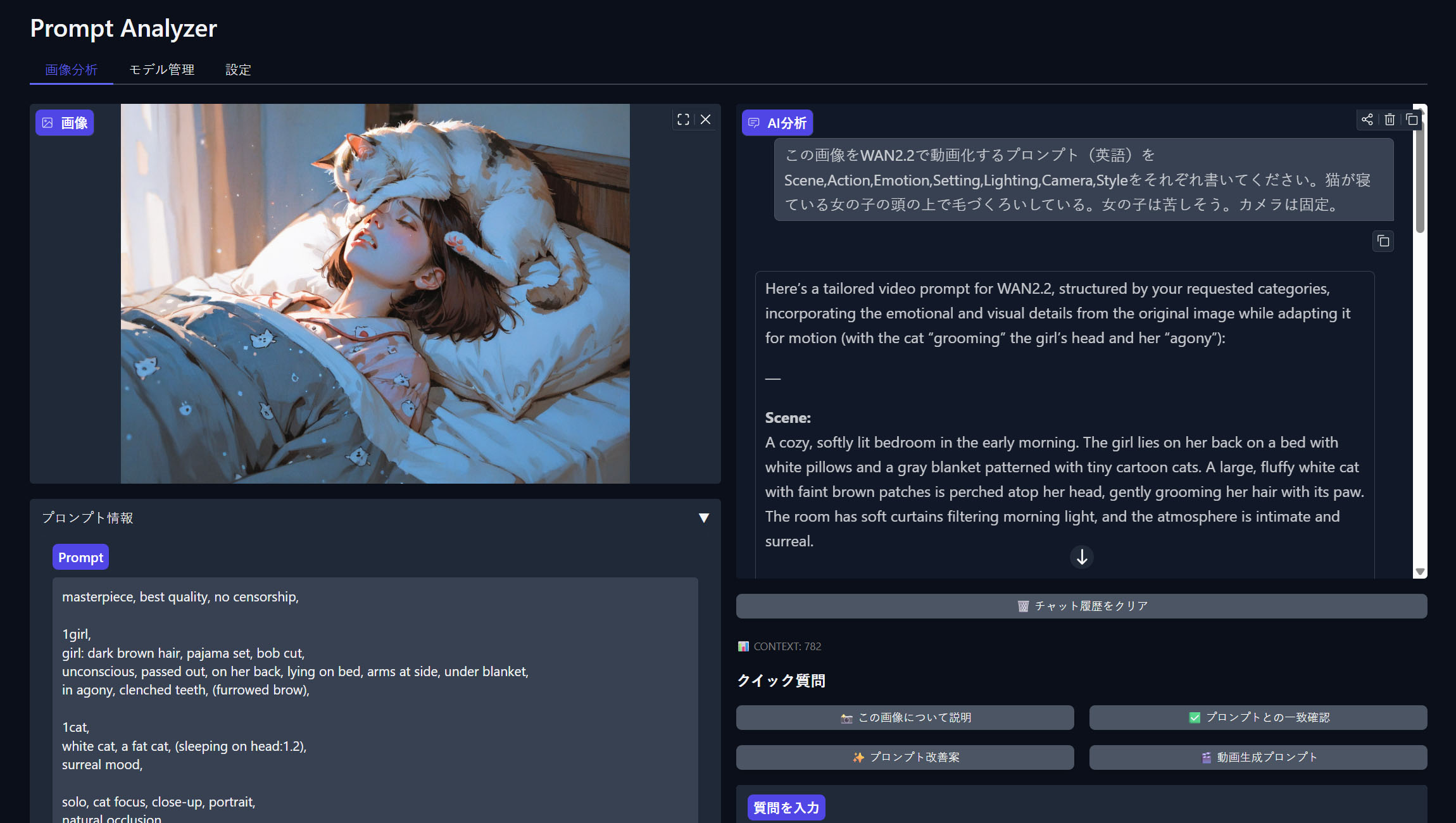
動画プロンプトの生成
プロンプトを元に動画生成用のプロンプトを書いてくれます。すでにある情報はプロンプトと画像から自動で書いてくれます。これは予想外の産物でした。
仕様
リポジトリはこちら
フレームワーク:Gradio(機械学習モデル向けのWeb UI作成ライブラリ)
推論エンジン:Transformers、PyTorch
視覚言語モデル:Qwen3-VL(Qwen VLモデル)
感想
Stable DiffusionやWANと同時に使うとだいぶ便利です。いちいちChatGPTにプロンプトの質問をするのって面倒なんですよね。ちょっとした需要にこそローカルLLMの威力が発揮されます。
今回もClaude Codeにほぼ作ってもらいました。こちらが勉強させてもらっている感じです。去年はAIのコード支援に感動していましたが、Claude Codeはそれを超えるレベルですね。もはやこれこそエージェントだと思います。